")
")
本文章用於紀錄與翻譯課程內容,請搭配google課程服用
本篇為第二篇 若未觀看第一篇的話建議先移至透過GCP-NL API進行文字主題分類 (1)
單元課程連結:
https://google.qwiklabs.com/focuses/1749?parent=catalog
分類一篇文本 Classify a news article
終於,我們要開始分類文本了(第一次用設定真的覺得很久QQ)
透過呼叫GCP 自然語言API底下的classifyText模組(方法, method),你可以將文字資料分類至文字主題類別。這個模組會根據所傳文字內容進行運算,最後回傳一個清單,清單所包含的是文字內容所適合的主題。
可能回傳的主題與分類說明可以參考這邊:here.
回傳的內容主題可能寬泛 像是`/Computers & Electronics`
也可能很精準如 ` /Computers & Electronics/Programming/Java (Programming Language).`A full list of 700+ possible categories can be found here.
簡單說明完API後,我們要使用這個API來開始解析單篇文章與大型新聞資料庫。
首先我們取用New York Times article的食物類別底下的一篇文章來實驗
文章內容如下:
A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes.
為了要發出http requests - post請求API進行解析,我們要先新增一個檔案,並且將檔案命名為 request.json ,內容為我們要解析的文章:(請直接複製內容貼進檔案裡)
{
"document":{
"type":"PLAIN_TEXT",
"content":"A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes."
}
}而創立的方式有兩種:
1.use the Cloud Shell code editor
2.使用 vim等文字編輯器
vim request.json
現在我們使用 curl 去打擊API,指令如下:
curl "https://language.googleapis.com/v1/documents:classifyText?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
正常回應如下:
{ categories:
[
{
name: '/Food & Drink/Cooking & Recipes',
confidence: 0.85
},
{
name: '/Food & Drink/Food/Meat & Seafood',
confidence: 0.63
}
]
}像這個例子API回應了兩個類別,分別是:
/Food & Drink/Cooking & Recipes/Food & Drink/Food/Meat & Seafood
該文章內容沒有明確提到這是一個食譜,甚至包括海鮮,但API能夠對其進行分類。
以上針對如何對一篇文章進行分類進行說明,但要真正看到這個功能的強大功能,讓我們對大量的文章內容數據進行分類。以下為範例。這個範例會使用到資料庫的概念與功能,假若沒有預計使用GCP的資料庫的話,以下可以略過。
對文字資料庫進行分類 Classifying a large text dataset
讓我們來看看如何透過classifyText功能幫助我們了解巨大文字的資料庫,這個範例我們會使用公開的BBC新聞資料庫進行測試,這個資料庫包括從2004到2005年的2,225篇文章,這些文章來自五個預設主題(商業、娛樂、政策、運動、科技),這些文章有一些位於公共Google雲端資料庫中。每篇文章都在.txt文件中。
為了處理這些資料並送到API,我們要來寫一個Python程式,這支程式要從Google雲端資料庫抓到資料且然後去將資料傳送至classifyTextAPI,最後把結果儲存回BigQuery的資料表裡面。
BigQuery 是 Google 的雲端大數據資料庫工具
– it lets you easily store and analyze large data sets.
假使你想要查看您將使用的文本類型,請在GCP的命令列運行以下命令查看一篇文章(gsutil 是 Cloud Storage的命令列界面):
gsutil cat gs://text-classification-codelab/bbc_dataset/entertainment/001.txt
接下來我們要在BigQuery中建立資料表來存放API的辨識結果。
在BigQuery中為文章的分類結果創建資料表
Creating a BigQuery table for our categorized text data
在將文本發送到Natural Language API之前,您需要一個位置來存儲每篇文章的文章內容和類別。
我們點選左邊選單中的BigQuery。
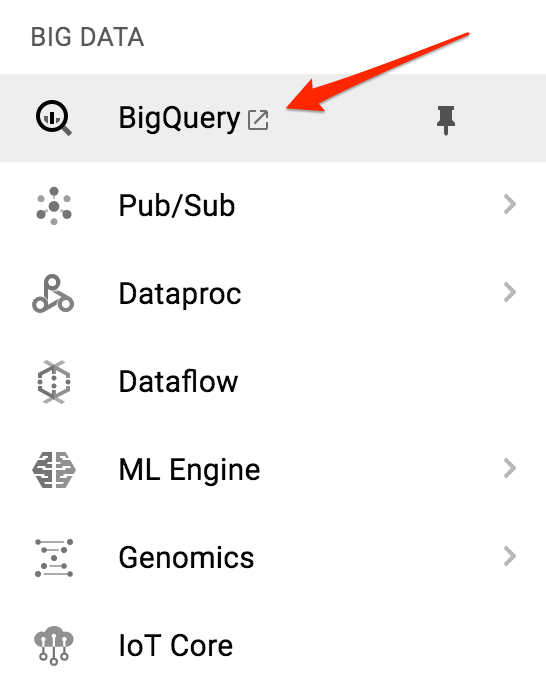
然後單擊項目名稱,然後點擊 “Create dataset”
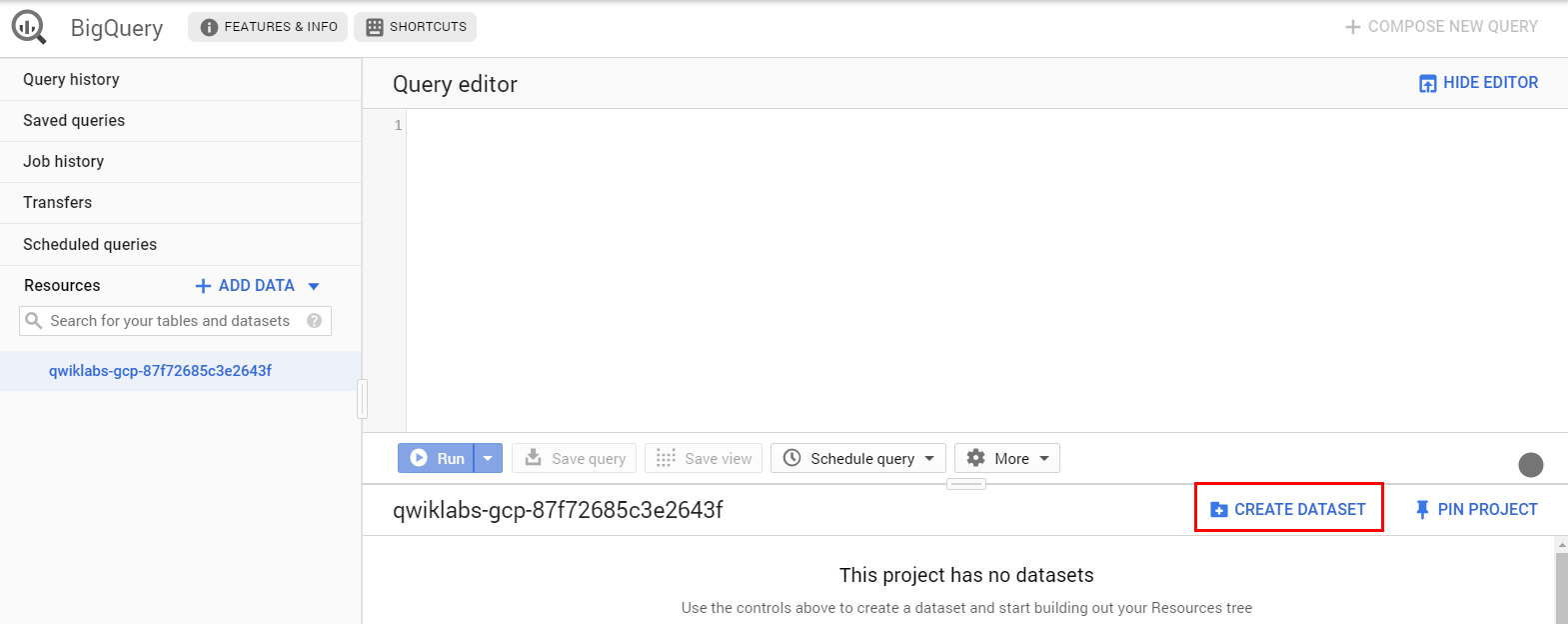
命名資料庫為“news_classification_dataset”
點擊“創建數據集”。
點擊數據集的名稱,然後選擇“創建新表”。
對新表使用以下設置:(由於介面是英文的,有些地方保留英文)
- Create From: empty table
- 命名資料表為 “article_data”
- 點選 “Add Field” ,我們要新增三個欄位: “article_text”, “category”, 和 “confidence”。
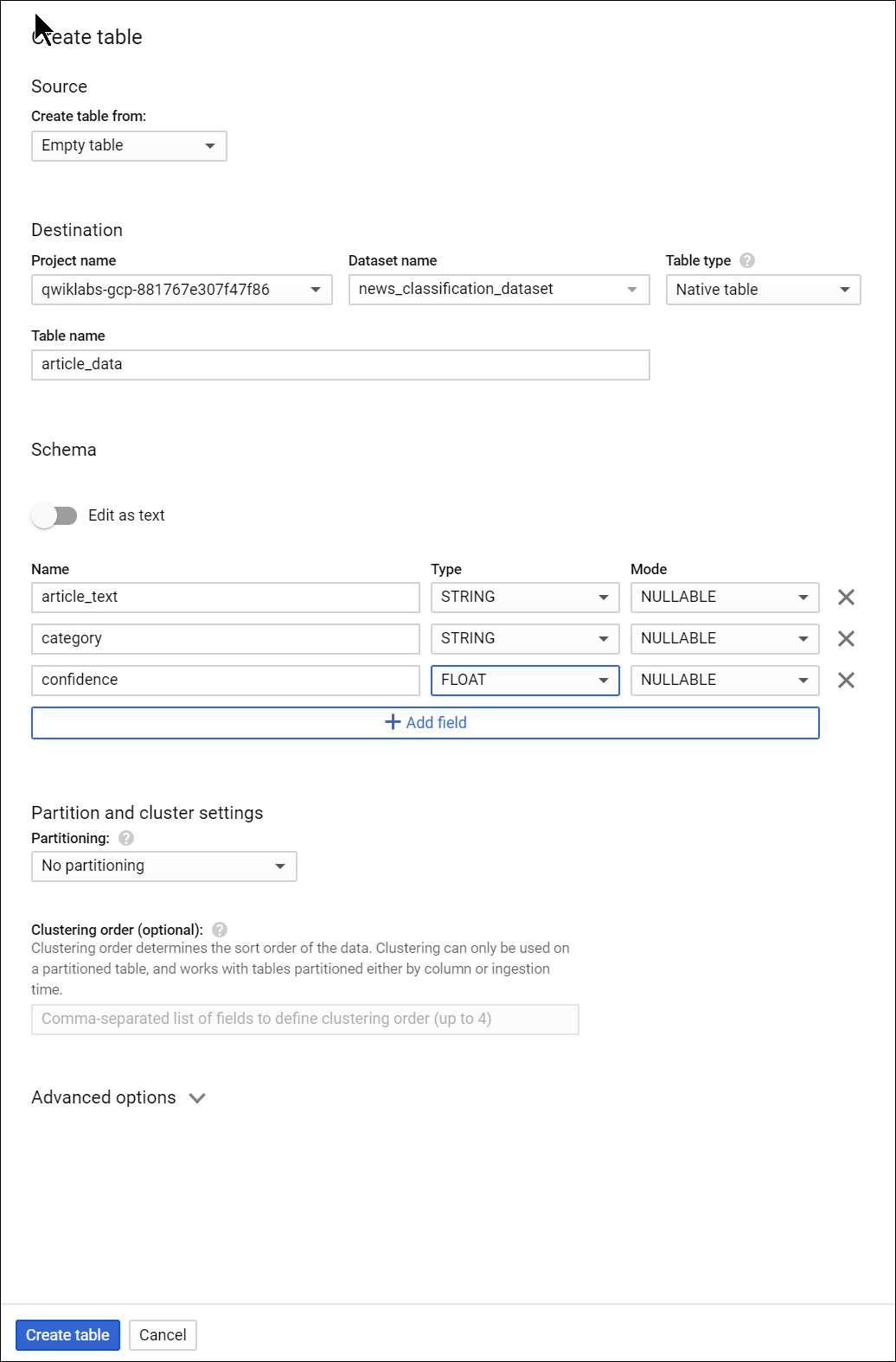
設定完後,點選 “Create Table”.
然後我們會得到一個空的資料表。
在下一步中,您將讀取Cloud Storage中的文章,將它們發送到Natural Language API進行分類,並將結果存儲在BigQuery中。
Classifying news data and storing the result in BigQuery
在我們編寫Python程式將新聞文章內容發送到API之前,您需要創建一個服務帳戶。這個帳戶將用於Natural Language API和BigQuery的驗證中。
首先,回到GCP的雲端命令列,我們要調整環境變數,
請在/*your GCP Project ID*/填入你的GCP Project ID 後執行。(GCP Project ID 應該在一開始開啟課程的介面可以找到)
export PROJECT= /*your GCP Project ID*/
然後在Cloud Shell運行以下命令以創建服務帳戶:
gcloud iam service-accounts create my-account --display-name my-account
gcloud projects add-iam-policy-binding $PROJECT --member=serviceAccount:my-account@$PROJECT.iam.gserviceaccount.com --role=roles/bigquery.admin
gcloud iam service-accounts keys create key.json --iam-account=my-account@$PROJECT.iam.gserviceaccount.com
export GOOGLE_APPLICATION_CREDENTIALS=key.json
現在您已準備好將文本數據發送到Natural Language API! 為此,請使用適用於Google Cloud的Python套件編寫Python程式。您可以使用任何語言完成相同的任務,有許多不同的雲客戶端庫。
現在我們建立Python程式,我們將它命名為 classify-text.py ,程式內容可以直接貼下方範例,一樣,不要忘了要去修正GCP Project ID欄位,請將YOUR_PROJECT取代成你的GCP Project ID。
from google.cloud import storage, language, bigquery
# Set up our GCS, NL, and BigQuery clients
storage_client = storage.Client()
nl_client = language.LanguageServiceClient()
# TODO: replace YOUR_PROJECT with your project id below
bq_client = bigquery.Client(project='YOUR_PROJECT')
dataset_ref = bq_client.dataset('news_classification_dataset')
dataset = bigquery.Dataset(dataset_ref)
table_ref = dataset.table('article_data') # Update this if you used a different table name
table = bq_client.get_table(table_ref)
# Send article text to the NL API's classifyText method
def classify_text(article):
response = nl_client.classify_text(
document=language.types.Document(
content=article,
type=language.enums.Document.Type.PLAIN_TEXT
)
)
return response
rows_for_bq = []
files = storage_client.bucket('text-classification-codelab').list_blobs()
print("Got article files from GCS, sending them to the NL API (this will take ~2 minutes)...")
# Send files to the NL API and save the result to send to BigQuery
for file in files:
if file.name.endswith('txt'):
article_text = file.download_as_string()
nl_response = classify_text(article_text)
if len(nl_response.categories) > 0:
rows_for_bq.append((article_text, nl_response.categories[0].name, nl_response.categories[0].confidence))
print("Writing NL API article data to BigQuery...")
# Write article text + category data to BQ
errors = bq_client.insert_rows(table, rows_for_bq)
assert errors == []
現在,您已準備好開始對文章進行分類並將其導入BigQuery。運行以下Python程式:
python classify-text.py
該程式大約需要兩分鐘才能完成,因此在運行時我們將討論程式的細節內容。
在程式中,我們使用google-cloud的Python套件來連接雲端資料庫、Natural Language API和BigQuery。
首先,我們為每個服務創建一個接口;然後創建引用到BigQuery表。
files 是對公共存儲桶中每個BBC數據集文件的引用。我們依序處理這些文件,並透過字串方式將文章下載下來,並將每個文章發送到classify_text函數中的Natural Language API。
並將Natural Language API回傳類別的所有文章、文章及其類別數據保存到rows_for_bq列表中。完成每篇文章的分類後,使用insert_rows()將數據插入到BigQuery中。
回到BigQuery介面,點選“article_data”,然後在點選“Query Table”
下個SQL來查詢資料庫的資料。
SELECT * FROM `YOUR_PROJECT.news_classification_dataset.article_data`
打好上行程式之後,點選 “Run”.
查詢完成後,您將看到您的數據。向右滾動可查看類別列。
類別列儲存了API針對文章分類的第一個類別,可信度是介於0和1之間的值,表示API對文章的正確分類有多大的信心。
您將學習如何在下一步中對數據執行更複雜的SQL查詢。
Analyzing categorized news data in BigQuery
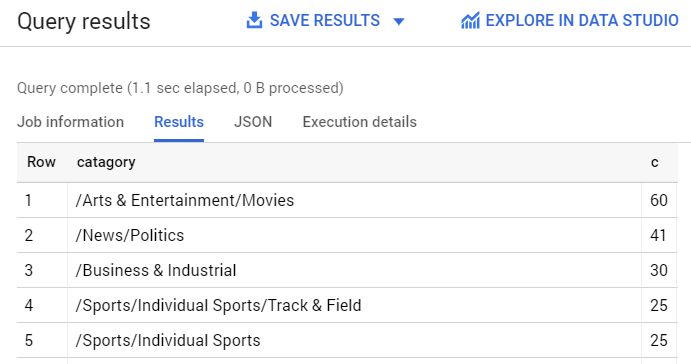
首先,查看數據集中最常見的類別。
在BigQuery控制台中,點擊“Compose New Query”。
輸入以下查詢,將YOUR_PROJECT替換為您的項目名稱:
SELECT
category,
COUNT(*) c
FROM
`YOUR_PROJECT.news_classification_dataset.article_data`
GROUP BY
category
ORDER BY
c DESC
點選 “Run”
查詢結果應該如下
如果你想找到一個更加模糊的類別
像是如分類至/ Arts&Entertainment / Music&Audio / Classical Music的文章
你可以寫下面的查詢
SELECT * FROM `YOUR_PROJECT.news_classification_dataset.article_data`
WHERE category = "/Arts & Entertainment/Music & Audio/Classical Music"
或者,您只想獲得分類的可信度得分大於90%的文章:
SELECT
article_text,
category
FROM `YOUR_PROJECT.news_classification_dataset.article_data`
WHERE cast(confidence as float64) > 0.9
To perform more queries on your data, explore the BigQuery documentation. BigQuery also integrates with a number of visualization tools. To create visualizations of your categorized news data, check out the Data Studio quickstartfor BigQuery.
要對數據執行更多查詢,請瀏覽BigQuery文檔。 BigQuery還包含許多可視化工具。要創建分類新聞數據的可視化,請查看Data Studio快速啟動BigQuery。
Congratulations! 恭喜!
您已經學習瞭如何使用Natural Language API文本分類方法對新聞文章進行分類。
您首先對一篇文章進行了分類,然後學習瞭如何使用帶有BigQuery的NL API對大型新聞數據集進行分類和分析。
您已經學習瞭如何使用Natural Language API文本分類方法對新聞文章進行分類。您首先對一篇文章進行了分類,然後學習瞭如何使用帶有BigQuery的NL API對大型新聞數據集進行分類和分析。
![[科技奇點]台灣「新創追星」計畫再傳捷報:立方衛星升空,加速太空技術驗證與商業化](https://s.yimg.com/fz/api/res/1.2/MaEOiI2xLWyC1iHiTjsdwA--~C/YXBwaWQ9c3JjaGRkO2ZpPWZpbGw7aD05MjtweG9mZj0wO3B5b2ZmPTA7cT04MDtzbT0xO3c9MTY0/https://media.zenfs.com/ko/youthdailynews_517/8bd8930c14243b0f194b18394a25be1e "[科技奇點]台灣「新創追星」計畫再傳捷報:立方衛星升空,加速太空技術驗證與商業化")
1 thought on “透過GCP-NL API進行文字主題分類 (2)”